Andmeteadlase töö praktikas: tehnoloogiad ja tööülesanded
Statistika selle kohta, milliseid tehnoloogiaid enim kasutatakse ja mida andmeteadlased ise oma tööülesannete kohta ütlevad.
Meediafirma O’Reilly Euroopa andmeteaduse 2017. aasta palgauuring sisaldab muuhulgas infot kõige populaarsemate tehnoloogiate kohta. Kuna see vihjab õppivale andmeteadlasele, mis on kõige väärtuslikumad tehnilised oskused, teen allpool sellest kokkuvõtte.
Tööriistad
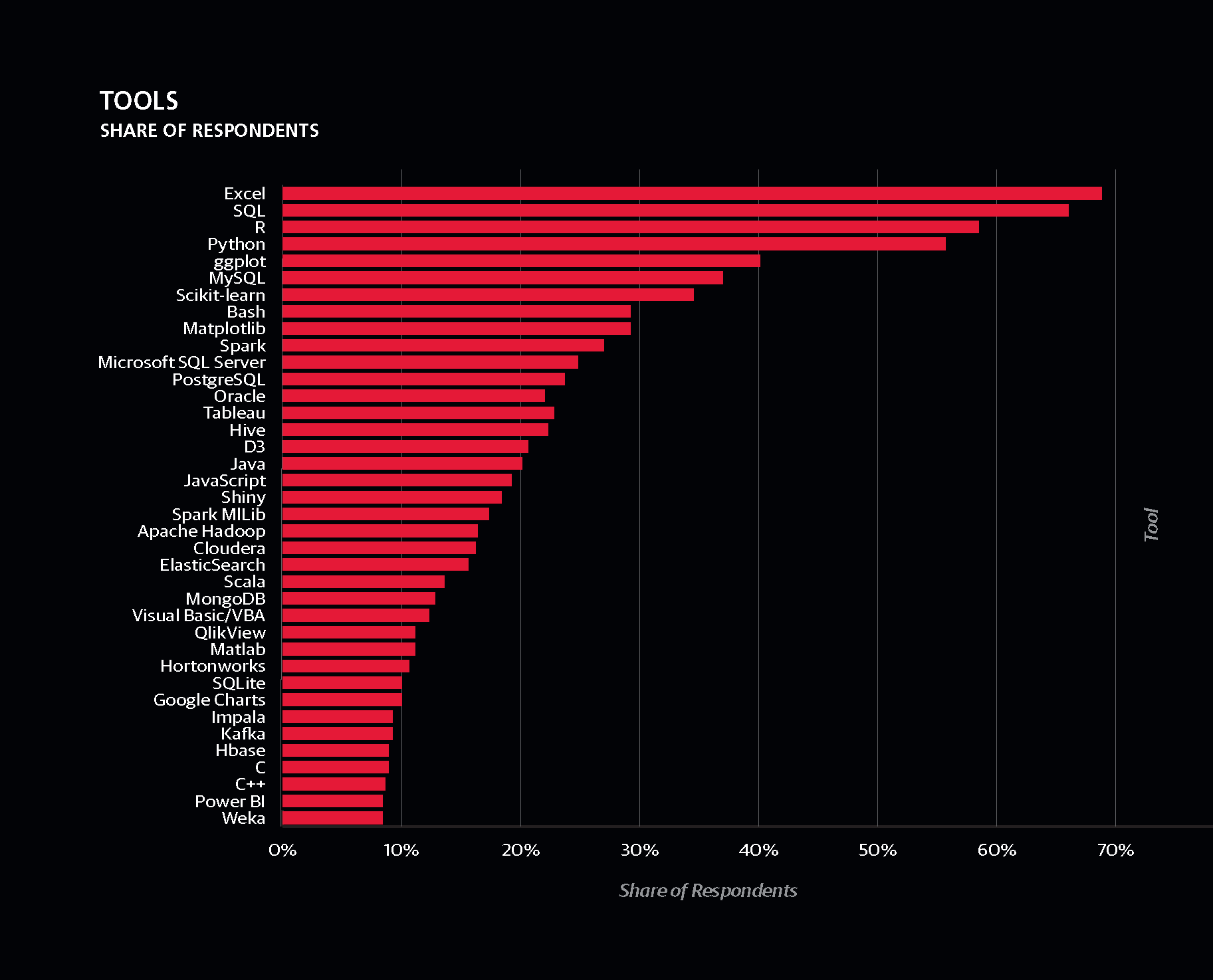
- Excel, Python, R ja SQL – neist igaüht kasutab üle poole andmeteadlastest.
- scikit-learn (Pythoni teek), Spark ja Hive (klasterarvutuse tööriistad) ja Scala (programmeerimiskeel) on tööriistad, mida kasutavad keskmisest enam teenivad andmeteadlased.
- Andmeteadlased, kes kasutavad palju eri tööriistu, teenivad keskmisest rohkem.
Siin joonisel on toodud eri tehnoloogiate populaarsus (see ja järgmised joonised pärinevad ülalnimetatud O’Reilly uuringust):
Järgnev joonis näitab tehnoloogiat kasutavate andmeteadlaste palgavahemikke (Eesti kontekstis tasub vaadata pigem suhtelisi, mitte absoluutseid arve):
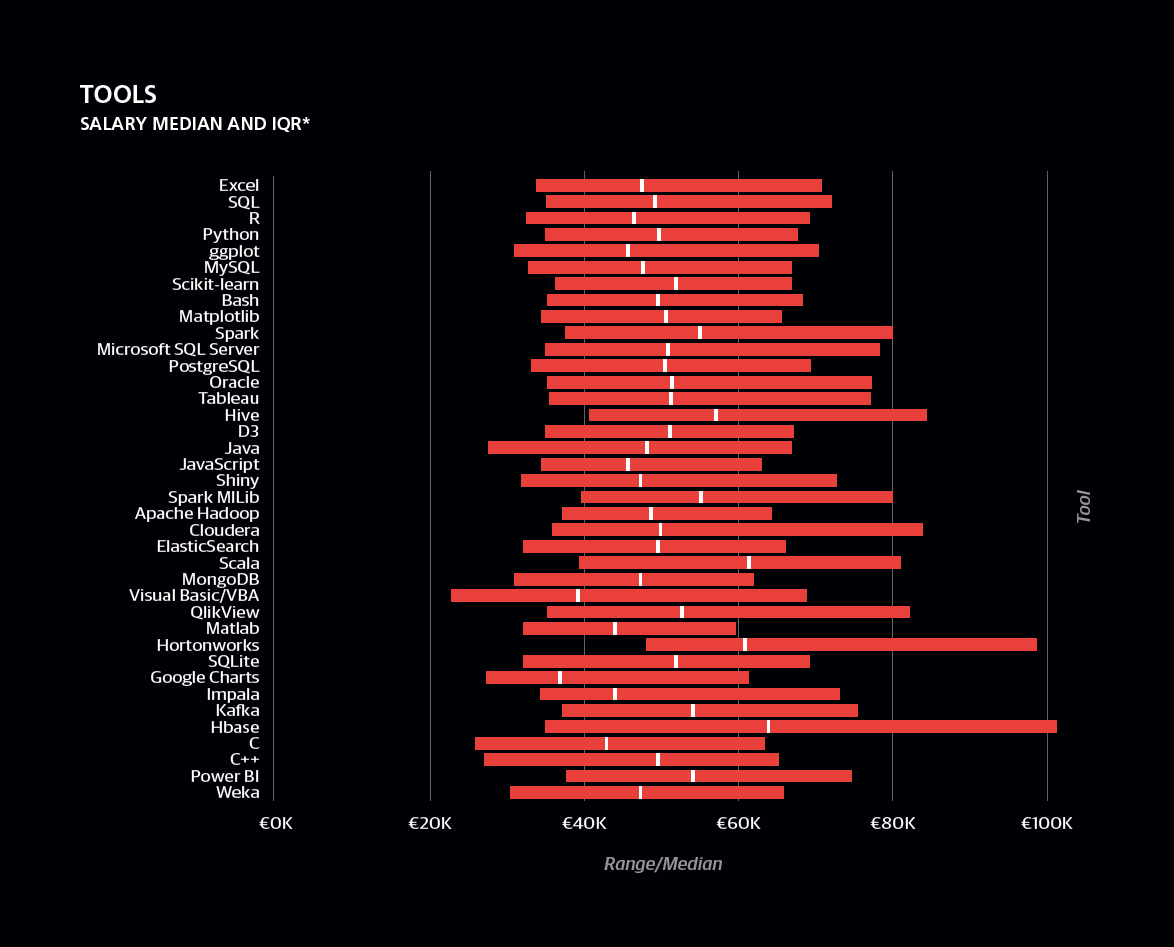
Ülaltoodu erineb küll veidi Eestis toimuvast. Taivo kogemusel on kõige enam kasutuses R ja Python ning Scala vähem. Samuti ei ole Eestis palju firmasid, kellel oleks vaja kasutada suuri klastreid (ja seega Sparki või Hive’i), seega soovitan siiski alustada Pythoni või R-iga ja liikuda sealt edasi.
Tööülesanded
Mida teevad andmeteadlased? Teame, et nad tegelevad andmetega, aga täpsemalt? See joonis annab hea vastuse ja läheb kokku Taivo senise kogemusega:
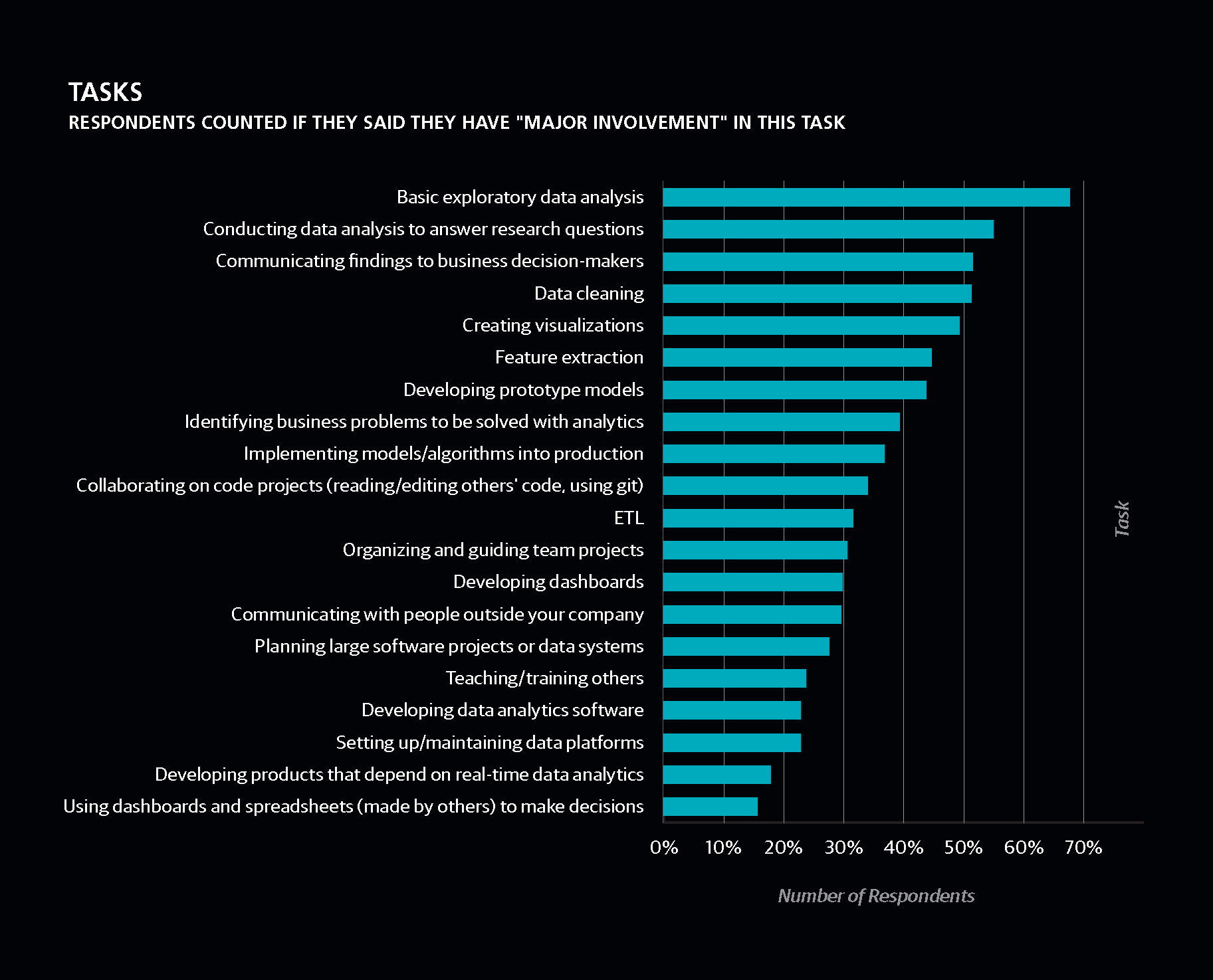
Kui tahad lähemalt teada, milline (statistiliselt) andmeteadlase töö välja näeb, loe O’Reilly raportit ise siit.